2024. 10. 30. 03:29ㆍAlgorithms
최장 공통 부분 수열(Longest Common Subsequence, LCS) 알고리즘은 두 문자열에서 순서대로 공통으로 나타나는 가장 긴 부분 수열을 찾는 문제입니다. 특히, 텍스트 비교, 유전자 서열 분석, 데이터 중복 검출 등 다양한 분야에서 활용되며 동적 프로그래밍(Dynamic Programming) 기법을 배우는 데 중요한 예제로 자주 사용됩니다.
이번 포스팅에서는 LCS의 개념, LCS 문제 해결을 위한 접근 방식과 구현 방법을 차례대로 살펴보겠습니다.
1. 최장 공통 부분 수열 (LCS)의 개념
LCS란 두 문자열의 공통된 부분 수열 중 가장 긴 것을 의미합니다. 여기서 부분 수열은 문자열의 일부 요소를 순서를 유지하며 선택한 문자열로, 반드시 연속될 필요는 없습니다.
예를 들어, "ABCBDAB"와 "BDCAB"라는 두 문자열이 있을 때, LCS는 "BCAB" 또는 "BDAB"가 될 수 있으며, 이 경우 LCS의 길이는 4입니다.
2. LCS 문제 해결 접근 방식
LCS 문제는 일반적으로 동적 프로그래밍을 사용하여 효율적으로 해결할 수 있습니다. 동적 프로그래밍을 통해 두 문자열의 각 문자를 비교하고 결과를 저장하여, 중복 계산을 줄이는 방식으로 시간 복잡도를 감소시킵니다.
기본적인 아이디어
- 두 문자열을 각각 행(row)과 열(column)로 설정하여 2차원 테이블을 생성합니다.
- 두 문자열의 각 문자를 비교해가며 다음 규칙을 따라 테이블을 채워갑니다:
- 두 문자가 같으면, 이전 대각선 값에 1을 더하여 현재 위치에 저장합니다.
- 두 문자가 다르면, 왼쪽이나 위쪽의 값 중 큰 값을 현재 위치에 저장합니다.
점화식 정의
두 문자열 X와 Y에 대해, dp[i][j]가 X의 처음 i번째 문자와 Y의 처음 j번째 문자까지 고려했을 때의 LCS 길이라고 할 때, 점화식은 다음과 같습니다.
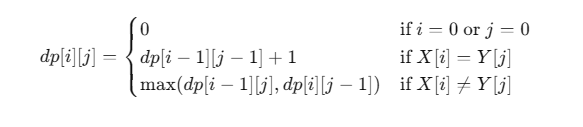
3. LCS 알고리즘 구현 (C#)
다음은 LCS 알고리즘을 C#으로 구현한 코드입니다.
using System;
public class LongestCommonSubsequence
{
public static int FindLCS(string X, string Y)
{
int m = X.Length;
int n = Y.Length;
int[,] dp = new int[m + 1, n + 1];
// LCS 테이블 채우기
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (X[i - 1] == Y[j - 1]) // 두 문자가 같으면
dp[i, j] = dp[i - 1, j - 1] + 1;
else
dp[i, j] = Math.Max(dp[i - 1, j], dp[i, j - 1]); // 두 문자가 다르면 큰 값 선택
}
}
// LCS 길이 반환
return dp[m, n];
}
public static void Main()
{
string X = "ABCBDAB";
string Y = "BDCAB";
int lcsLength = FindLCS(X, Y);
Console.WriteLine($"LCS의 길이: {lcsLength}");
}
}
4. 코드 설명
- dp 배열 초기화:
- dp[i][j]는 X의 처음 i개의 문자와 Y의 처음 j개의 문자 사이의 LCS 길이를 저장합니다.
- 배열의 첫 행과 열은 0으로 초기화하여, 문자열의 길이가 0일 때 LCS 길이가 0이 되도록 설정합니다.
- 두 문자의 비교:
- X[i-1] == Y[j-1]인 경우 대각선 위치(dp[i-1][j-1]) 값에 1을 더하여 dp[i][j]에 저장합니다.
- 두 문자가 다르면, 왼쪽(dp[i][j-1])이나 위쪽(dp[i-1][j])의 값 중 큰 값을 선택합니다.
- 결과 반환:
- 최종적으로 dp[m][n]에 저장된 값이 X와 Y의 최장 공통 부분 수열의 길이입니다.
5. 시간 복잡도와 공간 복잡도
- 시간 복잡도: 이 알고리즘의 시간 복잡도는 O(m * n)입니다. 두 문자열의 각 문자 쌍에 대해 비교를 수행하기 때문입니다.
- 공간 복잡도: 2차원 배열 dp를 사용하므로 공간 복잡도는 O(m * n)입니다.
LCS를 구하는 방법은 대부분 O(m * n)의 시간 복잡도를 가지며, 큰 문자열에서 효율적으로 사용하려면 공간 복잡도를 줄이는 방법이 필요할 수 있습니다.
6. LCS의 실제 사용 사례
LCS 알고리즘은 두 문자열의 공통 부분을 찾는 문제에 적합하여 다양한 응용 분야에서 사용됩니다.
- 파일 비교: 텍스트 파일의 차이점을 비교하거나 버전 간 변경 사항을 확인할 때 LCS가 활용됩니다.
- 유전자 서열 분석: 유전자 서열의 공통 부분을 찾아 생물학적 유사성을 확인하는 데 사용됩니다.
- 데이터 중복 검출: 데이터베이스나 텍스트에서 중복된 내용을 찾는 데 도움이 됩니다.
LCS는 단순히 문자열 간의 가장 긴 공통 부분을 찾는 문제를 넘어, 문자열의 유사도 측정과 알고리즘 최적화에 중요한 역할을 합니다. 동적 프로그래밍의 활용과 점화식의 중요성을 배우는 데 훌륭한 예제이며, 다양한 응용 문제에서 실용적인 해결책을 제공합니다.
LCS 알고리즘을 이해하고 코드로 구현해 보면서, 문자열 비교 문제에 대한 이해도를 높일 수 있습니다. 여러 가지 문제를 해결하면서 LCS 알고리즘을 유연하게 활용해 보세요!